This is an interactive Powderworld simulation! Click and drag to place elements.
Introduction
As the AI research community moves towards general agents, which can solve many tasks within an environment, it is crucial that we study environments with sufficient complexity. An ideal "foundation environment" should provide rich dynamics that stand in for real-world physics, while remaining fast to evaluate and reset.
To this end, we introduce Powderworld, a lightweight simulation environment for understanding AI generalization. Powderworld presents a 2D ruleset where elements (e.g. sand, water, fire) modularly react within local neighborhoods. Local interactions combine to form wide-scale emergent phenomena, allowing diverse tasks to be defined over the same core rules. Powderworld runs directly on the GPU, allowing up to 10,000 simulation steps per second, an order of magnitude faster than other RL environments like Atari or Minecraft.
We hope Powderworld can serve as a starter-kit for studying multi-task generalization.
This release contains:
- The core Powderworld engine.
- A procedural generation algorithm for generating world states out of lines, circles, and squares of different elements.
- 160 hand-designed test states for measuring out-of-distribution generalization.
- OpenAI Gym environments for Powderworld-based RL tasks.
- Starter code to train RL agents and world models.
Powderworld is easily importable, and connects to your GPU via Pytorch.
Features
Modularity and support for emergent phenomena. The core Powderworld engine defines a set of fundamental rules defining how two neighboring elements interact. Elements only interact with a 3x3 local neighborhood, and each element has unique properties -- e.g. water spreads out, fire burns wood, etc.
Local interactions can also build up to form emergent wider-scale phenomena. For example, fire can burn through a wooden bridge, causing other elements to fall. By building complex worlds out of simple interactions, we can create tasks that are diverse yet share consistent properties, allowing agents to learn generalizable knowledge.
Sand Pile Water Flow Wood Burn Plant Spread Gas Rise Dust Explode
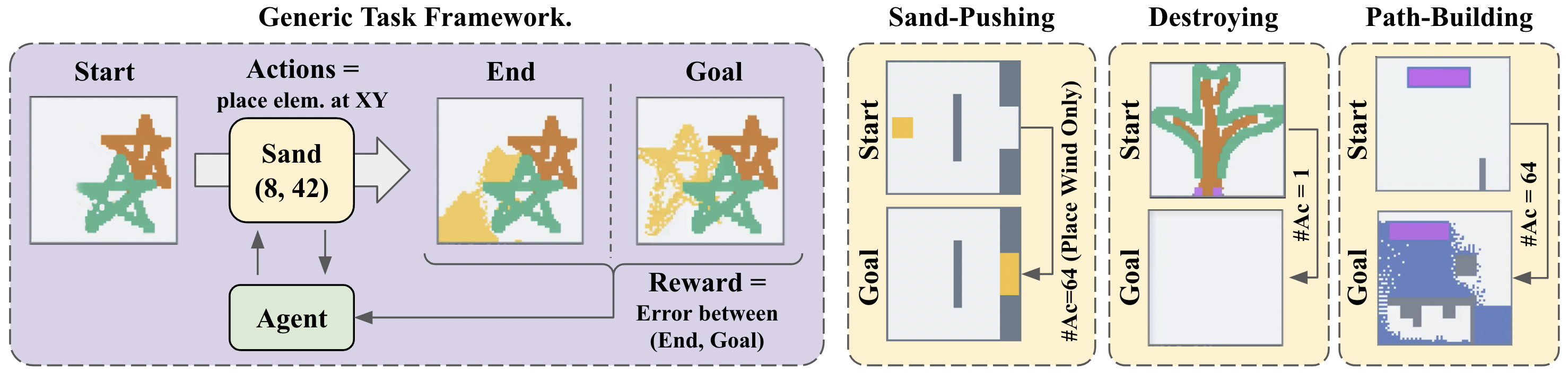
Expressive task design. Powderworld is designed to easily support many task varieties. For example, one task may be to construct a path for fire to spread, or another may be to build a bridge to direct water flow. The general task framework is as follows: agents are allowed to iteratively place elements, and must transform a starting state into a goal state.
Since tasks are defined as a series of 2D element arrays, they can be easily generated procedurally or via Unsupervised Environment Design techniques. We provide a simple procedural generation algorithm that can generate states out of elements in the shape of lines, circles, and squares. From these states, we can define tasks such as "create this scene", "destroy this scene", or "push this element".
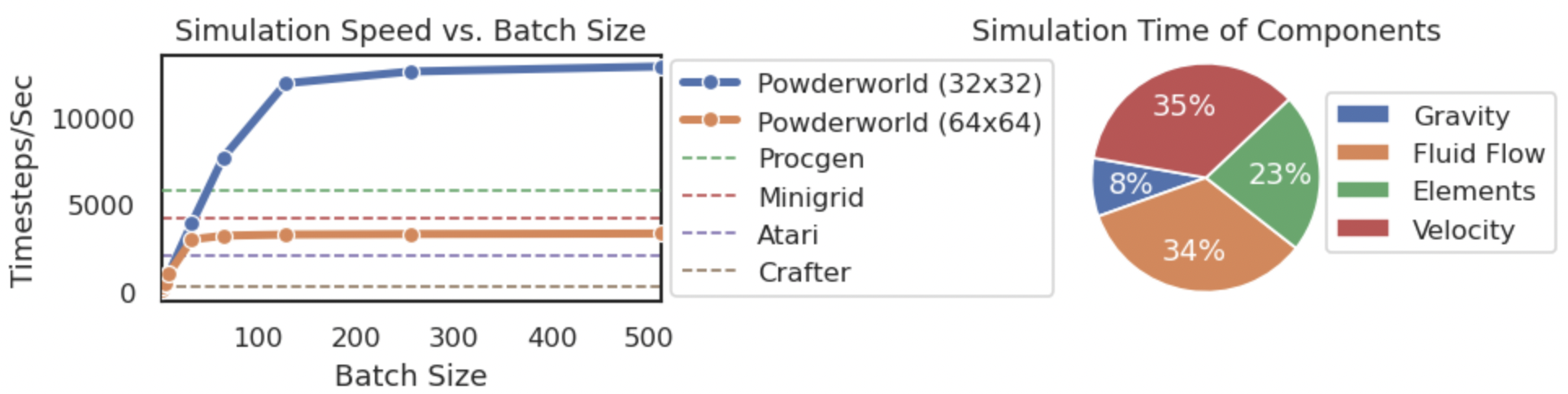
Fast runtime and representation. Powerworld runs on the GPU, enabling large batches of simulation to be run in parallel. Additionally, Powderworld employs a neural-network-friendly matrix representation for both task design and agent observations. To simplify the training of decision-making agents, Powderworld is fully observable and provides an observation of the shape (B, 20, H, W) where the feature dimension encodes the one-hot element, its qualities, and the velocity."
Baselines
We present a starting framework for training world models within Powderworld. Given an initial state, the world model aims to predict the future state after T=[1,4,8] timesteps of simulation. Since Powderworld presents a fully-observable Markovian state, it is unnecessary to condition on past observations or actions. A successful world model learns to approximate the Powderworld ruleset in a differentiable manner.
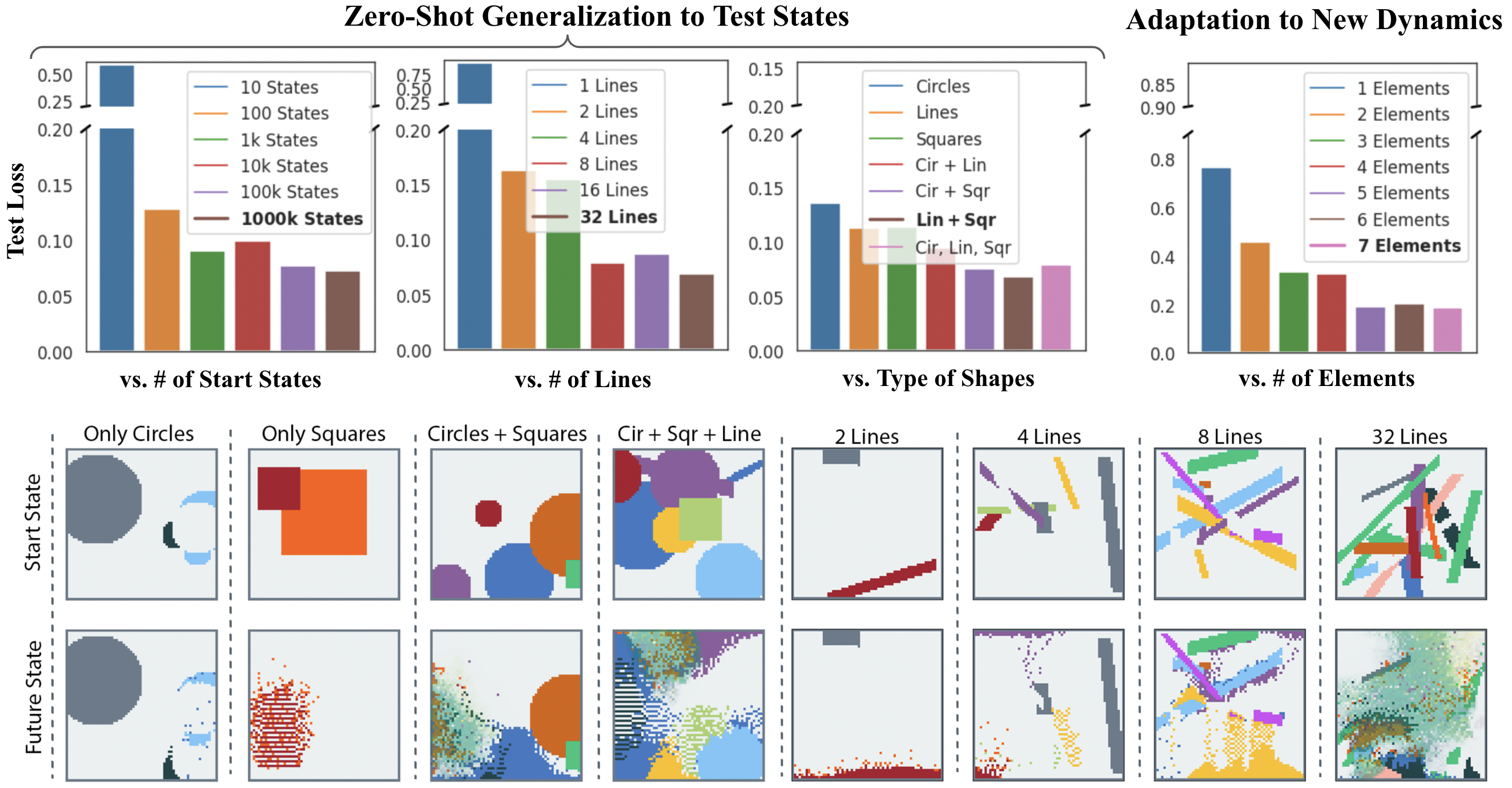
Powderworld experiments should examine generalization. Thus, we report world model performance on a set of held-out test states. We found that models trained on more complex training data (more shapes, more elements, etc) showed greater generalization performance.
World models pre-trained on more elements also showcase better performance when finetuned on novel dynamics. When transferring to an environment containing three held-out elements (gas, stone, acid), models exposed to more elements during training perform better. These results show that Powderworld provides a rich enough simulation that world models learn adaptation-capable representations. The richer the simulation, the stronger these representations become.
We also provide a set of reinforcement learning tasks within Powderworld, along with baseline agents. Agents are allowed to interact with the world by placing elements at an XY location. Depending on the task, agents may have objectives ranging from "create this object" to "burn down this scene". In all cases, we focus on studying stochastically-diverse tasks, where starting/goal states are procedurally generated, and agents must solve unseen challenges during test time.
It is simple to define novel tasks within the Powderworld framework. For example, we define the "sand-pushing" task by specifying a start state with a cache of sand, and a goal state where the sand is in a different location. Agents are constrained to only place wind. To create a plant-growing task, one could create starting states with dots of plants, and allow agents to place water to grow these plants to a larger size.
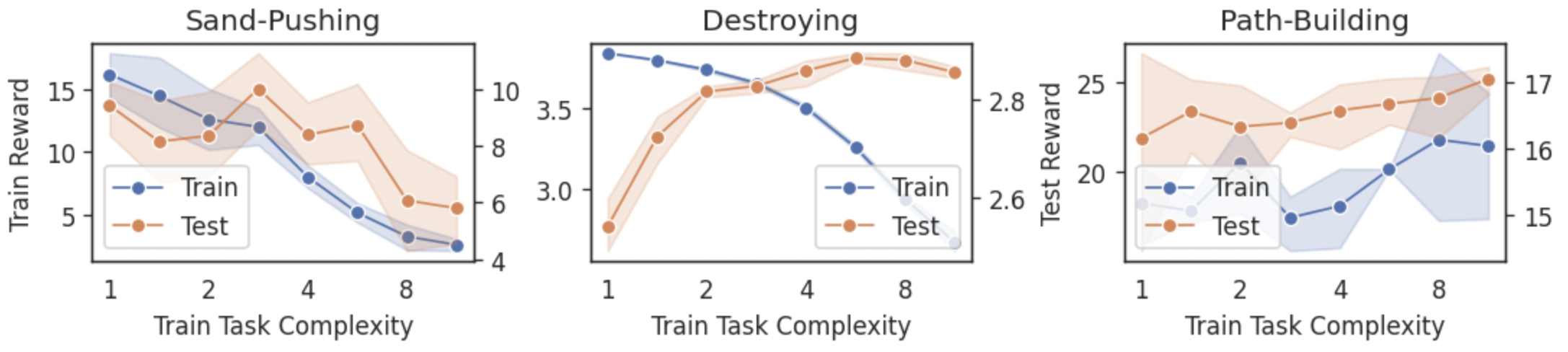
Experiments show that increasing training task complexity helps with generalization, up to a task-specific inflection point. Diversity in training tasks allows agents to learn robust policies, but overly complex training tasks create instability during reinforcement learning.
The difference in how complexity affects training in Powderworld world-modelling and reinforcement learning tasks highlights a motivating platform for further investigation. While baseline RL methods may fail to scale with additional complexity and instead suffer due to variance, alternative learning techniques may better handle the learning problem and show higher generalization.
Sand Pushing. Create wind to manipulate sand into a goal slot. By producing wind, agents interact with the velocity field, allowing them to push and move elements around. Wind affects the velocity field in a 10x10 area around the specified position. Reward equals the number of sand elements within the goal slot, and episodes are run for 64 timesteps. The Sand-Pushing task presents a sparse-reward sequential decision-making problem.
Destroying. Place a small number of elements to efficiently destroy a world. Agents are allowed to place elements for five timesteps, after which the world is simulated forwards another 64 timesteps, and reward is calculated as the number of empty elements. A general strategy is to place fire on flammable structures, and place acid on other elements to dissolve them away. The Destroying task presents a contextual bandits-like task where correctly parsing the given observation is crucial.
Path-Building. Place/remove wall elements to funnel water into a container. An episode lasts 64 timesteps, and reward is calculated as the number of water elements in the goal. Water is continuously produced from a source formation of Cloner-Water elements. In the Path-Building challenge, agents must strategically place blocks such that water flows efficiently in the correct direction. Additionally, any obstacles present must be cleared or built around.