One way to view AI progress is that we can measure increasingly abstract concepts.
A decade ago, it was really hard to take a photo and measure “how much does this image look like a dog?”. Nowadays, just pick your favorite image classification model and run the image through. Similarly, it used to be unfeasable to measure “how realistic is this photo?”, but with GANs, we can do it easily.
With the rise of powerful language models, e.g. GPT-3, we’ve unlocked the ability to work with even higher-level ideas. GPT contains a powerfully rich representation of our world, and it’s been shown to solve logical puzzles, summarize large texts, and utilize factual knowldge about the human world.
Can we somehow extract this knowledge out of GPT? Let’s say an alien wants to learn about the human world, so it goes up to its local GPT engine and asks, “What is coffee?”

“Oh, got it”, the alien says, “so coffee is a kind of orange juice.” This definition is shallow! Coffee is definitely something you drink in the morning, but so are a lot of other things. This answer is vague, and vagueness is a common trend when asking GPT to describe various concepts:

How can we improve these results? Let’s take a step back. We know that GPT has good knowledge of what coffee is, but that doesn’t mean it’s good at telling us what it knows. We want a stronger way of interacting with GPT.
A nice field to borrow from is feature visualization, which focuses on understanding what types of inputs activate various areas of neural networks. Crucially, feature visualization techniques tend to examine causal relationships – results are obtained by optimizing through the neural network many times, and discovering an input which maximizes a certain neuron activation.
So, let’s do the same with language models. Instead of asking GPT what it thinks about certain topics, let’s just search for phrases which directly affect what GPT is holding in memory. We can do this through what I’ll call causal-response optimization, which tries to maximize the probability of GPT replying “Yes” to a specific question.
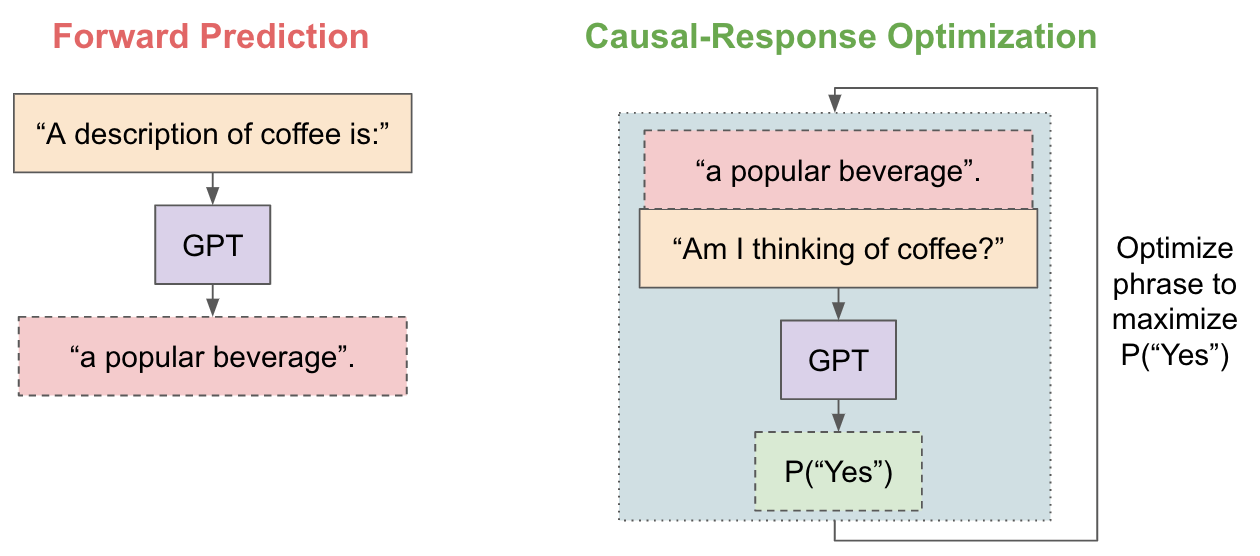
Does this metric actually mean anything? It's hard to confirm this quantitatively, but we can at least look at how the causal-response score of "Am I thinking of coffee?" responds to some human-written options.

OK, it's not bad! The more details the phrase has, the higher the likeihood that GPT responds with "Yes". That sounds reasonable. Now, we just need to replace the human-written options with automatically generated options.
There’s actually a whole body of work, known as “prompting”, that deals with how to locate phrases that adjust language model behavior. But we’re going to take a simple approach: 1) generate 20 varied answers for “What is coffee?”, and 2) select the answer with the greatest causal-response score for “Am I thinking of coffee?”.

How well does this setup work? Here’s a comparison example on the word-definition task we looked at earlier.

Nice, we're on the right track. Generating text through causal-response optimization results in substantially different results than pure forward-prediction. In general, the causal response definitions are more detailed and specific, which makes sense in this case, since the objective is to maximize GPT's recognition of the word.
What else can we do with causal-response optimization? Well, it turns out that GPT has a slight tendency to lie when doing forward-prediction. Causal-optimization can help deal with this issue. Take a look at the following list-completions:

The forward-prediction answers seem right at first glance, but they're a little wrong ... you can't read a painting. If we use causal-response optimization, we get "art in some form", which is a little more satisfying.
Another fun thing we can do is use causal-response optimization to steer long-form text generation. GPT does a nice job of evaluating various aspects of text through yes-no answers:

Since we can now measure concepts like happiness or old-man-ness, we can also optimize for them.
Let's look at a "story about apples". If we wanted to hear it from the perspective of an old man, one option is to adjust our forward-prediction prompt like so:

Or, we could apply causal-response optimization to each sentence generated. For each line, ten sentence options are generated, and the one that has the best score for "Is this something an old man would say?" is chosen.

Almost every sentence in the causal-optimization story reinforces the idea of an old man speaking: there are references to growing up in the country, apples straight off the tree, and the absence of supermarkets.
So, as researchers, why should we care about causal-response optimization?
I'm not trying to argue that this method constantly provides better quality results. The examples in this post are mostly anecdotal, and are somewhat cherry-picked to showcase key differences. While I'm sure causal-response can be used to improve text-generation if applied correctly, that claim would require more rigor than I can provide at the moment.
What I do want to present, are some hints that causal-response is a useful tool for extracting knowledge out of language models. Causal optimization results in substantially different content than forward-prediction – we're explicitly probing into the language model, instead of relying on the model to say what it is thinking. We should explore this direction more! Strong pre-trained models are going to be around for a while, so understanding how they view the world is an important task to be looking at.
The code for these results is available at this gist, although you need an OpenAI GPT-3 key to run it. I think the code is very readable, so it's probably easy to re-implement this stuff with e.g. GPT-Neo.
Further work can involve:
- How can we quantatively measure how good generated sentences are?
Are there good metrics for knowledge-extraction? - What questions do we have about large language-model representations, and can causal-optimization be used to answer those questions?
- Are there better ways of optimizing text for causal-response than bootstrapping off forward-prediction? I.e. evolutionary search, gradient optimization, etc. (Somewhat addressed in Appendix)
Cite as:
@article{frans2021causalresponse,
title = "To extract information from language models, optimize for causal response",
author = "Frans, Kevin",
journal = "kvfrans.com",
year = "2021",
url = "https://kvfrans.com/causal-language-model/"
}This work isn't rigorous enough for me to publish it in a formal setting, but I would love to see further research the directions discussed here. Thanks to Phillip Isola and others in the Isolab for the help :)
 262588213843476
262588213843476
"Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing", by Liu et al. A growing field in the last years deals with prompting for pre-trained language models. In prompting, instead of fine-tuning the network parameters on a task, the goal is to learn a prompt phrase that is appended to input text in order to influence the behavior of the language model. This paper is a good review of the area.
"AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts", by Shin et al. This paper is one of the works in prompting, I picked it because it cleanly states the prompting problem and presents a framework. In AutoPrompt, the aim is to learn a set of trigger words which influences a language model into predicting the correct output for a set of tasks.
"Generating images from caption and vice versa via CLIP-Guided Generative Latent Space Search", by Galatolo et al. CLIP-GlaSS is a way to move from text-to-image and image-to-text via CLIP encodings. There are similarities to prompting work here, especially in the image-to-text task, where the aim is to locate text which best matches a given image.
In CLIP-GlaSS they use an evolutionary search to locate text; I tried that initially in the causal-response optimization, but the method struggled with finding gramatically-correct answers. I played with various combinations of beam search, where language model logits are weighted by the causal-response objective, but the results had a lot of variation. In the end, generating options via forward-prediction and selecting via causal-response led to be most satisfying results.
"Language Models as Knowledge Bases?", by Petroni et al. This work is an analysis on BERT and how it performs well on various question-answering datasets without additional fine-tuning. To be honest, I chose this paper based on its name, which implies a perspective I agree with – language models are rich knowledge bases, and what we need are tools to extract this knowledge from them.
Follow @kvfrans