AI-assissted art has always been intriguing to me. To me, visual art is a very human thing -- I can’t imagine a way that a computer rediscovers our own cultural concepts without some kind of experience living in our world. So when AI methods are able to learn from us, and produce artwork that we as humans might make ourselves, something cool is definitely happening.
This post presents CLIPDraw, a text-to-drawing synthesis method that I’ve been playing with nonstop for the past few weeks. At its core, CLIPDraw is quite simple, yet it is able to produce drawings that display a whole range of interesting behaviors and connections. So for this article, I want to focus on showing off behaviors of CLIPDraw that I personally found intriguing and wanted to learn more about. For more detailed analysis and technical detail, check out the CLIPDraw paper, or play around with the Colab notebook yourself!

Image Synthesis -> Drawing Synthesis
The field of text-to-image synthesis has a broad history, and recent methods have shown stunningly realistic image generation through GAN-like methods. Realism, however, is a double-edged sword – there's a lot of overhead in generating photorealistic renderings, when often all we want are simple drawings. With CLIPDraw, I took inspiration from the web game Skribbl.io, where players only have a few seconds to draw out a word for other players to guess. What if an AI could play Skribbl.io? What would it draw? Are simple shapes enough to represent increasingly complex concepts?


How does CLIPDraw work?
CLIPDraw's knowledge is powered through a pre-trained CLIP model, a recent release which I definitely reccommend reading about. In short, a CLIP model consists of an image encoder and a text encoder, which both map onto the same represenational space. This setup allows us to measure the similarities betweeen images and text. And if we can measure similarities, we can also try to discover images that maximize that similarity, therefore matching a given textual prompt.
The basic CLIPDraw loop follows this principle of synthesis-through-optimization. First, start with a human-given description prompt and a random set of Bezier curves. Then, gradually adjust those curves through gradient descent so that the drawing best matches the given prompt. There are a few tricks that also help, as detailed in the paper, but this loop is basically all there is to it.
Now, let's examine what CLIPDraw comes up with in practice.
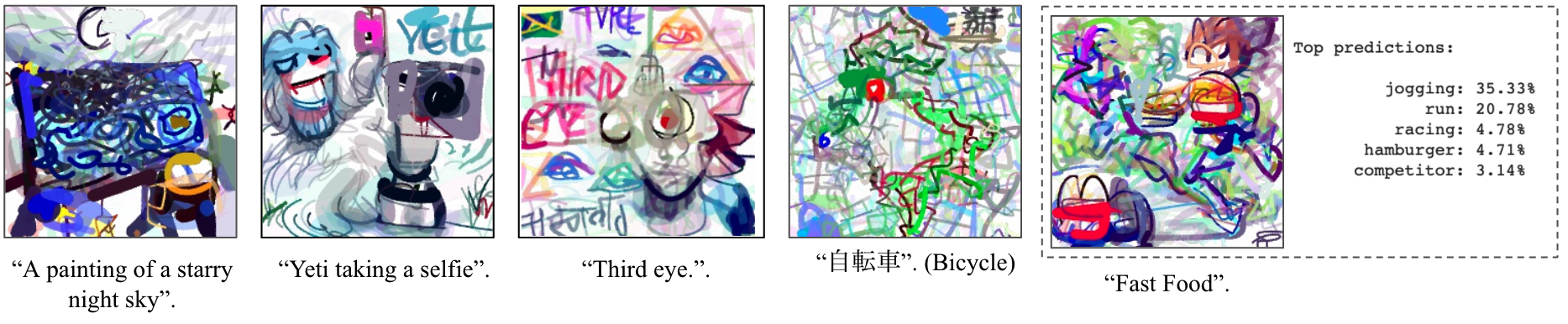
What visual techniques does CLIPDraw use?
A reoccuring theme is that CLIPDraw tends to interpret the description prompts in multiple, unexpected ways. A great example for this is "A painting of a starry night sky", which shows a painterly-styled sky with a moon and stars, along with an actual painting canvas and painter in the foreground, which then also features black and blue swirls resembling Van Gogh's "The Starry Night".
CLIPDraw also likes to use abstract symbols, the most prominent being when it writes out the literal word inside the image itself. Sometimes, CLIPDraw will use tangentially related concepts, like the Google Maps screenshot when asked for "自転車 (Bicycle in Japanese)”. A fun result is the prompt for "Fast Food", which shows hamburgers and a McDonald's logo, but also has a bunch of joggers racing in the background.

How does CLIPDraw react to different styles?
An experiment I really enjoyed was to synthesize images of cats, but in different artistic styles. With CLIPDraw, this was as easy as changing the descriptor adjectives of the textual prompt. Surprisingly, CLIPDraw is quite robust at handling different styles, contrary to the initial intent to synthesize scribble-like drawings.
One interesting feature is that CLIPDraw adjusts not only the textures of drawings, ala Style Transfer methods, but also the structure of the underlying content. In the cat experiments, asking for "a drawing" produces a simplified cartoonish cat, while prompts like "a 3D wireframe" produce a cat in perspective, with depth and shadows.

Does stroke count affect the drawings that CLIPDraw produces?
A key aspect of CLIPDraw is that drawings are represented as a set of Bezier curves rather than a matrix of pixels. This feature gives us a nice parameter to tweak in the number of curves a drawing is comprised of.
Emperically, drawings with low stroke counts tend to result in a more cartoonish or abstract representation of the prompt, such as the 16-stroke version of "The Eiffel Tower" being basically made of a few straight lines. As stroke count is increased, CLIPDraw begins to target more structured shapes, shown as our Eiffel Tower begins gaining 3D perspective, lights, and finally a background.

What happens if abstract words are given as a prompt?
A fun thing to push the limits is to give CLIPDraw abstract descriptions, and see what it does with them. As a human artist, even I would have to stop and think about how to convey these concepts through visuals, so it's interesting to see how the AI will approach things.
In most cases, CLIPDraw likes to use symbols to showcase concepts that are culturally related to the given phrase, like the fireworks and smiles in "Happiness" or the Japanese and English-like letters in "Translation".
My favorite here is the drawing for "Self", which features a body holding up multiple heads. The drawing can almost be seen as a metaphor for e.g. the idea that a person's self may contain multiple outward personalities, or that a self is actually a sum of many cognitive processes. This piece is defintely the most "art-like" example I came across; there's a lot of room for individual interpretation, and it almost feels like CLIP knows something that I don't.
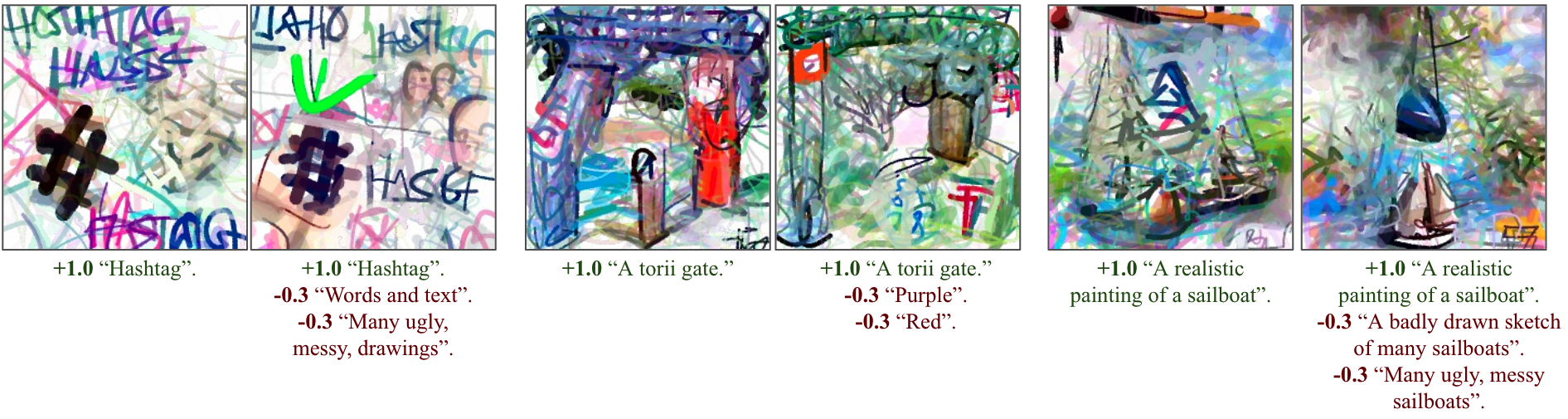
Can drawings be fine-tuned via negative prompts?
A final experiment was to see if CLIPDraw behavior could be finely adjusted by introducing additional optimization objectives. In the normal process, drawings are optimized to best match a textual prompt. What if we also tried to optimize unsimilarity with a set of negative prompts?
In a few situations, this works! By penalizing the prompt for "Words and text", the "Hashtag" drawing features less prominent words and instead draws a set of selfie-like faces. Negative prompts can also do things like adjust the color of images, or force drawings to contain only a single subject rather than many.
Practially, the examples above were pretty hard to achieve, and most of the time negative prompts don't change much about the final drawing at all. I think there's still a lot of room for experimentation on how to improve this technique. One thing I'd love to see is a panacea prompt, like "A messy drawing", that consistently improves drawing quality if used as a negative objective regardless of context.
CLIPDraw: Parting Thoughts
The CLIPDraw algorithm isn't particularly novel; people have doing synthesis-through-optimization for a while through activation-maximization methods, and recently through CLIP-matching objectives. However, I do believe biasing towards drawings rather than photorealism gives images more freedom of expression, and optimizing Bezier curves is a nice way to do this efficiently. I also personally love this artstyle and I think the drawings are quite similar to what an artist would produce ;).
That being said, I do think the behaviors showcased here should be pretty generalizable to any CLIP-based optimization method. Already a few extensions come to mind – Can we synthesize videos? 3D models? Can an AI play Skribbl or Broken Picture Phone with itself? I'm sure you as a reader have a bunch of ideas I haven't even considered. So please, feel free to take this method and go wherever you feel is exciting. And then tell me about it!
You can experiment with the Colab notebook here, and play with CLIPDraw in the browser. Results are generally pretty quick (within a minute) unless you crank up stroke count and iterations. You can also check out the full paper, which contains a bit of a deeper analysis and details on the technical implementation.
Thank you to everyone at Cross Labs for assisstance and feedback.
"CLIPDraw: Exploring Text-to-Drawing Synthesis via Language-Image Encoders", by Frans et al. Of course a nice place to start is the paper for CLIPDraw! The paper mostly contains a similar focus on analyzing interesting behaviors, but also includes some comparisons and a Related Work section of good papers to read up on.
"CLIP: Connecting Text and Images", by Radford et al. This is the blog for the original CLIP release, from OpenAI. CLIP is a language-image dual encoder that maps text and images onto the same feature space. Trained on a huge amount of online data, CLIP ends up being super robust and can solve a bunch of image tasks without any additional training. (Paper)
"Differentiable Vector Graphics Rasterization for Editing and Learning", by Li et al. This work is the differentiable vector graphics methods that we use in CLIPDraw to backprop through Bezier curves. It's really impressive and basically works out of the box, so I highly reccommend giving it a read.
"Generative Art Using Neural Visual Grammars and Dual Encoders", by Fernando et al. This paper is another CLIP-based generative art method, also using stroke-based images, but with an emphasis on AI creativity. Instead of backprop, they use evolutionary methods to evolve a custom LSTM-based grammar which defines the strokes. Also their figures are cool.
"Images Generated By AI Machines", by @samburtonking. Also check out the Colab notebooks by @advadnoun and @RiversHaveWings, respectively. This twitter account basically shows off cool generative art made from CLIP + GAN optimization methods. A lot of interesting pieces have been made and it's well worth looking through.
"VectorAscent: Generate vector graphics from a textual description" by Ajay Jain. Here's a project from earlier this year that actually used the same techniques of combining CLIP and diffvg. The key difference is in the image augmentation, which seems to help in ensuring synthesized drawings look more consistent.
Follow @kvfrans