Open-endedness is the idea of a system that "endlessly creates increasingly interesting designs". That's a simple concept with big implications. Biological life on earth is diverse and beautiful and the result of open-ended evolution. Human culture is open-ended; we've created a lot of art and technology without any real plan.
For those of us interested in AI and the emergence of intelligence, open-endedness is especially important. Because even with powerful learning algorithms, intelligence is one of those tricky things that's hard and complicated to specify. But that's the beauty of open-ended systems: they can generate unexpected designs, designs that go beyond the intention of the designer. And so even if intelligence is hard to create, it might be possible to create a system where intelligence naturally emerges.
This weekend, a bunch of us thinking about how open-endedness can boost AI gathered at the Agent Learning in Open-Endedness (ALOE) workshop at ICLR. I had the pleasure of attending, and since this topic is really fascinating I took some notes, so here they are.
As context, I (Kevin Frans) am a master's student at MIT under Phillip Isola, and I've spent time at places like OpenAI and Cross Labs. The hypothesis I've been studying is: a strong learning algorithm, coupled with a rich enough set of tasks, will result in intelligence. We have strong learning algorithms, but our tasks are quite bad, so what are consistent principles for making task distributions that are rich, learnable, yet increasingly complex?
More tasks = smarter agents.
A common theme in AI is that we take the same basic learning algorithms, and scale them up with harder tasks, and they can discover more complicated behaviors. There's arguments of whether this fact is good or bad for research, but the fact is that it works, and accepting this can lead to cool practical results.
XLand, the new task set from Deepmind, works by accepting this lesson and pushing it to the limit. XLand aims to create a whole bunch of related tasks by 1) defining a distribution of games, and 2) making them all multi-agent.
The key lesson here is that distribution of XLand tasks is just so varied and dense. XLand tasks take place in a 3D physics world, and agents need to do things like move blocks around, catch other agents, or play hide-and-seek. These games are defined in a modular way, so some agents get reward based on Distance(Agent, Ball) while others are rewarded for -Distance(AgentA, AgentB). Each task also takes place on a procedurally-generated terrain. Tasks are inherently multi-agent, so the same task can have a different reward landscape based on which agents are involved.
Now that we've got a rich distribution of games, just train agents with RL and they will be smart. There's some fancy population-based training involved, but it's a side point, the main idea is that agents trained on this rich set of games have no choice but to become generally capable, and they do. Strong XLand agents perform well on a bunch of the tasks, even unseen ones, and seem to generally do the right thing.
To me, the nice part about XLand is that it confirms we can achieve strong generalization just by engineering the task space to be richer, denser, and larger. Now AGI is a game design problem, and game design is fun. The downside is that this all seems awfully expensive to compute.
Procedural content generation + AI.
My favorite video games can be replayed hundreds of times, and these games usually make use of procedural content generation (PCG). Instead of manually building out levels, we can define an algorithm that builds the levels for us, and use it to generate an infinite amount of content.
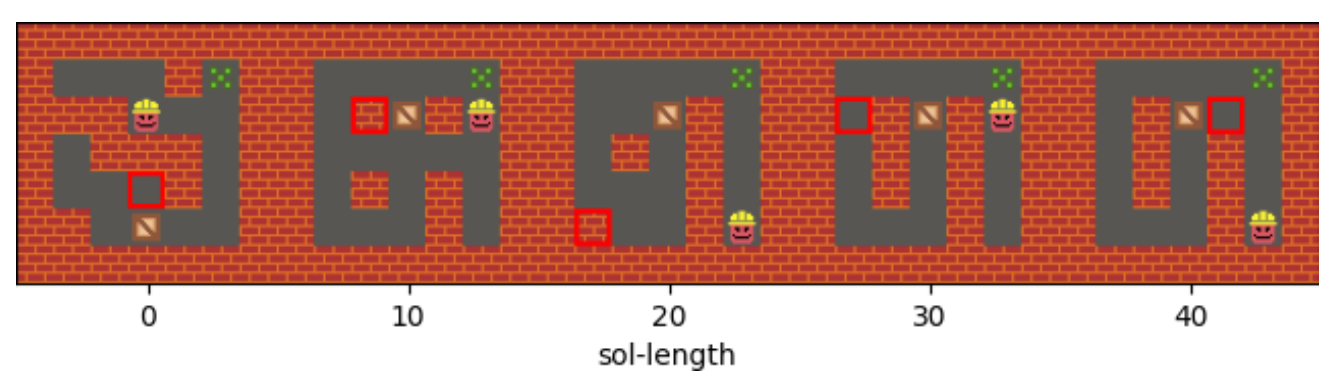
Sam Earle's work is on how PCG and AI intersect. First, can AI methods be used as a PCG algorithm? You could imagine PCG being a data modelling problem – given a set of 1000 Mario levels, train a GAN or autoencoder to model the distribution. But this is open-endedness, we're not satisfied with mimicry. Sam's early work on PCGRL frames content generation as a reinforcement learning task. If we can define a measurement of how good a level is, we can try and learn a generator that best fits this measurement. A follow-up paper takes this further, and lets the user specify a bunch of parameters like level-length or difficulty, which the AI generator does its best to fulfill.
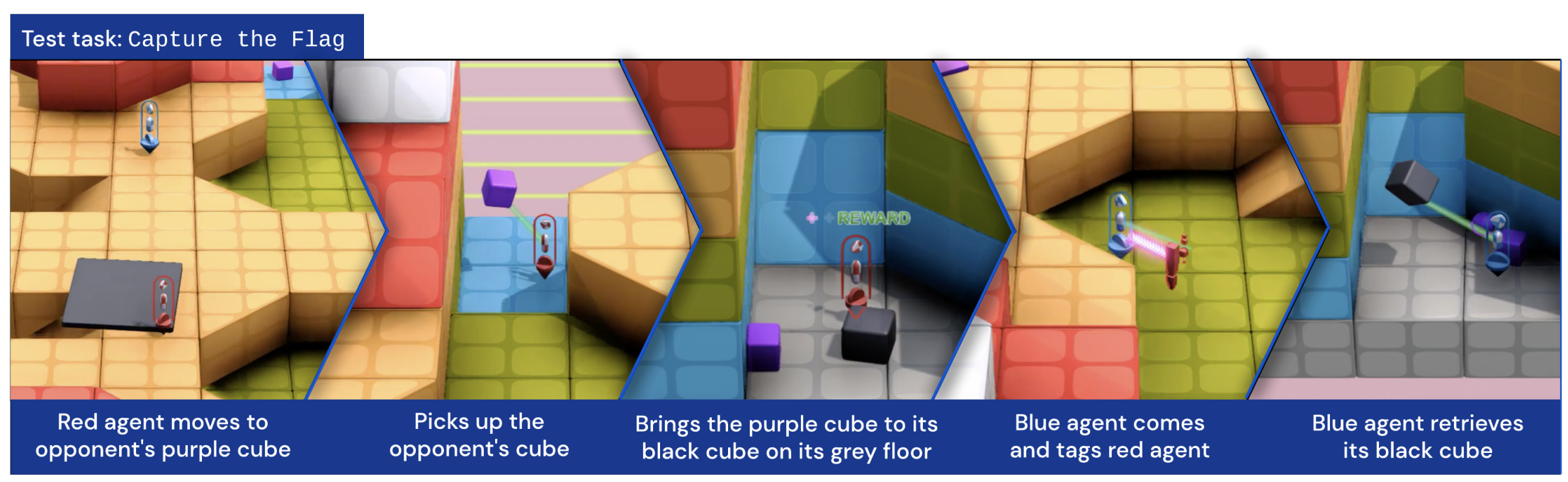
To me, the simplest open-ended loop is a zero-sum competitive game. Two players compete against each other, and adapt to each other's weakness in a continuous learning loop. So if we want to train a really good Mario-playing agent, it's crucial that we think just as hard about a Mario level-generating agent. That's where AI PCG methods come in – we're only going to get so far with human-made levels, so we're going to need to build generator agents that never stop learning.
The Tao of Agents and Environments
"Instead of a real presentation, here are some slides that I threw together in an hour", started Julius Togelius. "Actually I spent two days on this, but it's funnier to pretend I didn't." He then proceeded to show pictures of Agent Smith from The Matrix, and an environment diagram of the H2O cycle.
The purpose of all this was to point out that our classic framework of "agents interacting with an environment" is limiting. What if our environment has other agents in it? Why does the game-player have to be the agent? Can the environment be the player? If we start to question these terms, maybe there's new ground we can think about when it comes to "agent-based" systems.
From an open-endedness perspective, this idea makes sense, because we want to think of our systems as more than just optimization problems. A traditional reinforcement learning problem is to train a robotic agent to solve a control environment, it's clean and simple and solvable. But in an open-ended system, maybe we want the robot to compete against other robots. Maybe the real goal is not to develop strong robots, but to see the emergence of cooperation or communication. Maybe we care about these robots because we want to discover new challenges for new robots. In an open-endedness view, everything is adapting so everything is an agent, and everything affects everything else so everything is also an environment.
To see emergent complexity, use antagonistic pairs.
A fundamental open-ended loop is:
- Solve a task
- Generate a new task
- Repeat
Solving a task is well-studied, we have whole fields on how to do this. How to generate new tasks, however, is ripe for exploration. We need to be careful. If the tasks are too similar, then we're not learning anything new, but if the tasks are too distinct, an agent might not be able to solve them. Ideally, we want to define some implicit curriculum of tasks that an agent can gradually work its way through.
Past works on open-ended task generation include ideas like POET, where tasks are generated by 1) making 100 variations of a solved task, and 2) trying to solve as many of the variations as we can. This framework does work; but it's limited by the hard-coded method of making task variations. We can do something smarter.
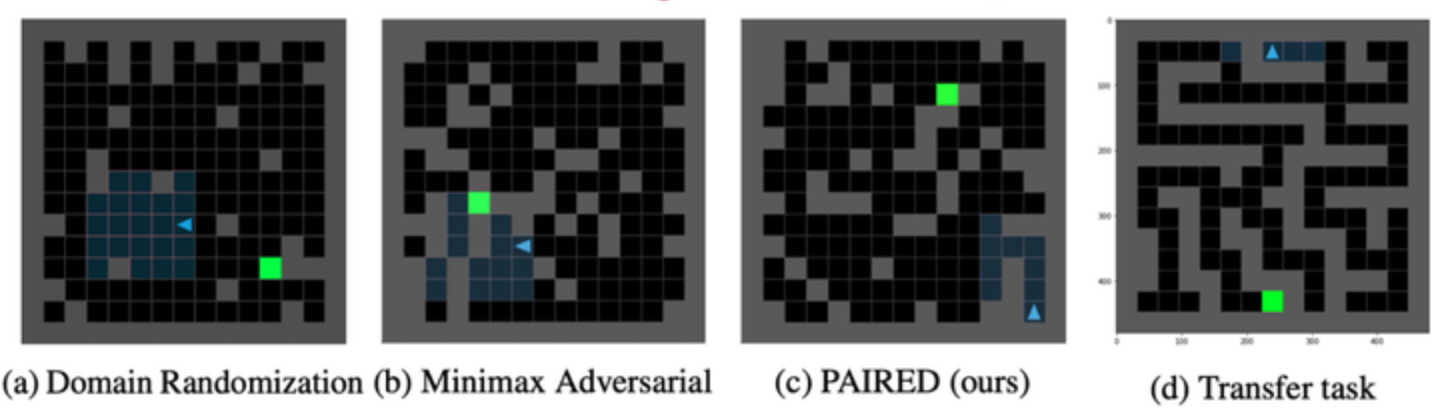
PAIRED, as presented by Natasha Jaques, presents a more adaptive way of generating tasks. If we think about the kinds of tasks we want, its tasks that the agent is just barely capable of solving. PAIRED proposes a heuristic using two agents, a protagonist and an antagonist, and a task generator. The generator tries to propose tasks that the protagonist can't solve, but the antagonist can. This way, we're always generating tasks in the sweet spot where they're solvable, but the protagonist hasn't quite figured it out yet. "Hey protagonist", says the generator, "here's a task that your brother the antagonist can solve, so I know you can solve it too, so start trying".
I think these little loops are quite powerful, and we just need to find better places to apply them. As a researcher, if I want to train a robust AI agent, I should try and parametrize a super-expressive distribution of tasks, then let loose an open-ended process to gradually expand what it can solve.
Panel Discussion
Along with the presentations, here were some fun thoughts from the panel discussions:
- Ken: What's the difference between AI and ALIFE? Well in AI we're somewhat focusing on economic value, whereas in ALIFE we really just care about what's cool.
- Ken: ALIFE focuses too much on evolution, which we don't really need. But in AI and machine learning, we need to work on weirder and braver ideas.
- Danijar: We need more open-ended environments. Atari is dumb, robotic control is too simple.
- Ken: Environmental design for OE is a deep field. It needs to be understood. What gives our universe properties that lets it sustain OE for so long?
- Julian: People who designed games like Skyrim and Elden Ring have figured out a bunch of heuristics that make good OE experiences.
- Danijar: Minecraft kind of has crafting, but it's not OE crafting, it's hardcoded. We want to have emergent crafting, but also be computationally feasable.
- Joel: The best part of ALIFE is the belief that it's totally possible to make life or life-like evolution, and it should be easy, and it's just right there.
- Moderator: Say you travel 10 years into the future, and there's an open-ended simulation that works. What does it look like?
- (everyone looks up and thinks)
- Joel: We tackle the meta learning objective. We optimize for human preferences, we tell a system to keep making cool stuff that is cool to us as humans.
- Natasha: Inter-group competition. We get something interesting where we have competition, and groups competing against each other, so we have cooperative stuff like language, communities, etc.
- Julian: The system is super diverse. There are many things going on. I don't know what the principles are, but I won’t understand what’s going on. The metrics look great, but it's like looking at a coral reef, I don't know what's going on but there’s pretty colors. Like a coral reef, there will be many extremely different kinds of things.
- Danijar: We get better and better at simulating some version of the real world, at a level of abstraction that is more and more accurate, maybe some MMO game to collect resources, or a mathematics environment where we discover more theorems.
- Ken: There’s so many possibilities its hard to say, at a low level there’s creatures in a world that are reminiscent of nature, there’s theorem proving, agents that are with humans in the web, OE interacting with humans.
For more, check out the ALOE proceedings and workshop.