When implementing DDPG-style policy extraction, we often use a tanh normalizer to bound the action space. That way the policy does not attempt to output something OOD when the Q-function is only trained on actions in [-1, 1].
dist = agent.actor(batch['observations'])
normalized_actions = jnp.tanh(dist.loc)
q = agent.critic(batch['observations'], normalized_actions)
q_loss = -q.mean()When I was writing code to execute the policy, I had forgotten to include this tanh shaping. So, it was using the raw actions, but clipped between [-1, 1]. Somehow, the performance was still basically at SOTA.
actions = agent.actor(observations).sample(seed=seed)
actions = jnp.tanh(actions) # We don't actually need this line.
actions = jnp.clip(actions, -1, 1)Question: Is it better to not apply tanh during evaluation? One hypothesis is that the policy can't actually output -1 or 1 using tanh, because the pre-activation has to approach infinity.
I ran experiments comparing the correct version (tanh applied during eval) with my clipped version (instead of tanh, clip the actions):
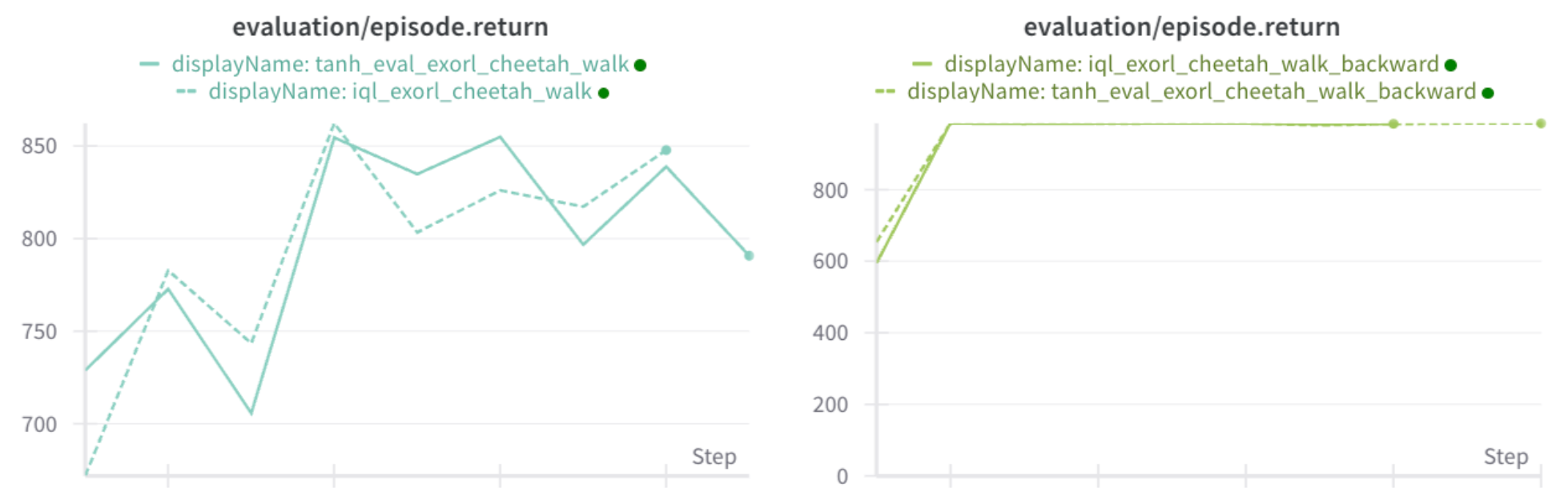
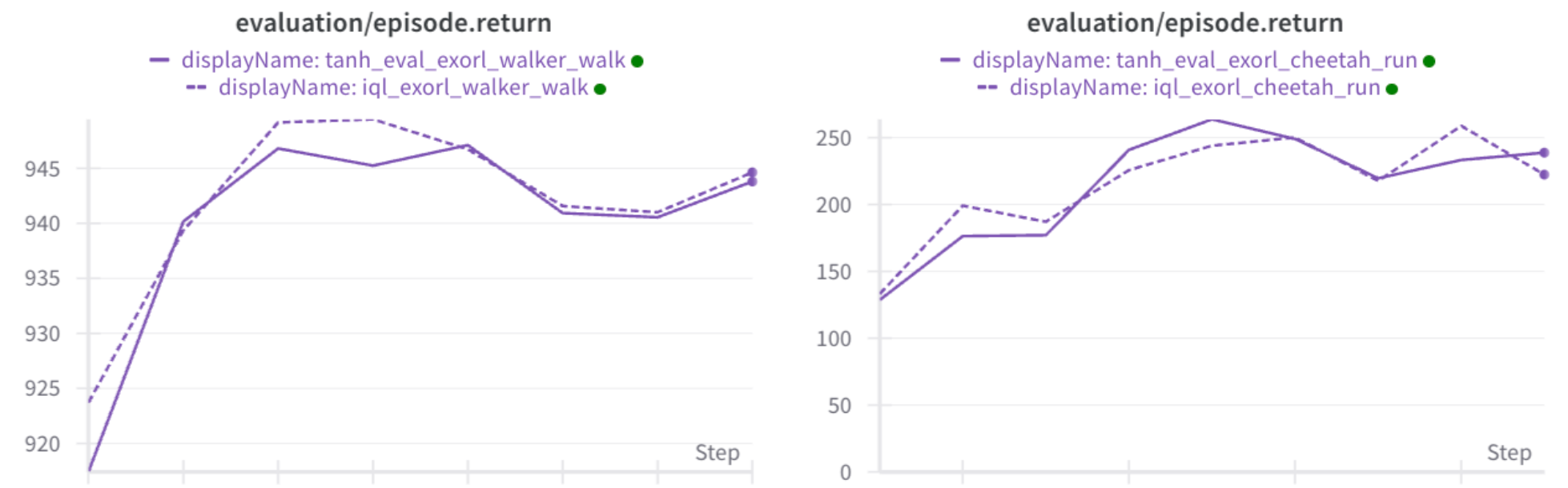
Conclusion: It doesn't actually matter. Both perform the same. DMC environments are known to be solvable with bang-bang control, so the policy is likely outputting actions close to -1 or 1, regardless of the tanh activation.