This post is a bunch of random thoughts about things I've read recently. It's organized into sections, and the sections don't really relate to each other, but here they are.
Neural Networks are Data Digesters
A common philosophy around my head is that "representation learning is everything". Need to label some images? Train a linear classifier over a powerful representation space. Need to navigate a robot to pick up some blocks? Train a simple policy over a strong representation of the robot. If you can map your input data into a general enough representation, everything becomes easy.
Eric Jang's blog post "Just Ask For Generalization" takes this philosophy a step further. If what we really need is strong representations, and neural networks are really strong sponges for absorbing data, then we might as well cram as much relevant data as we can into our models. Eric argues:
1. Large amounts of diverse data are more important to generalization than clever model biases.
2. If you believe (1), then how much your model generalizes is directly proportional to how fast you can push diverse data into a sufficiently high-capacity model.
To me, it feels like we're reaching diminishing returns in designing new models – e.g, transformers are highly effective at modeling everything from text to video to decision-making. Progress lies, instead, in how we can feed these models the data they need to properly generalize in whatever dimensions we care about.
One hypothesis is that we should give our models as much data as we can, regardless of how relevant the data is to the task at hand. Take, for example, language models – the strongest models are pretrained on billions of arbitrary texts from the internet. In reinforcement learning, we're starting to see the same parallels. Traditionally, agents are trained to maximize rewards on the task at hand, but it turns out we get sizable improvements by training agents to reach past states, achieve a range of rewards, or solve many mutations of the task.
If we believe this hypothesis, we should really be researching how to best extract relevant data for the task at hand. Should a strong RL agent be trained to achieve many goals instead of one, or to achieve a spectrum of rewards instead of optimal reward? Should its model be able to predict future states? To contrast augmented data from fake data? Should it be trained over thousands of games, instead of just one?
Machine Learning via Machine Learning
MIT offered a meta-learning class last year, which I really wanted to take, except I was away on gap year so I couldn't. The highlight of the class is to build "a system that passes 6.036 Introduction to Machine Learning as a virtual student". That's so cool! Thankfully the group behind the class released a paper about it, so here it is.
We generate a new training set of questions and answers consisting of course exercises, homework, and quiz questions from MIT’s 6.036 Introduction to Machine Learning course and train a machine learning model to answer these questions. Our system uses Transformer models within an encoder-decoder architecture with graph and tree representations ... Thus, our system automatically generates new questions across topics, answers both open-response questions and multiple-choice questions, classifies problems, and generates problem hints, pushing the envelope of AI for STEM education.
Summary-wise, they've got a Transformer model which reads in machine learning questions, and outputs a graph of mathematical operators which solve the questions. It seems to work quite well, and passes the class with an A (!).
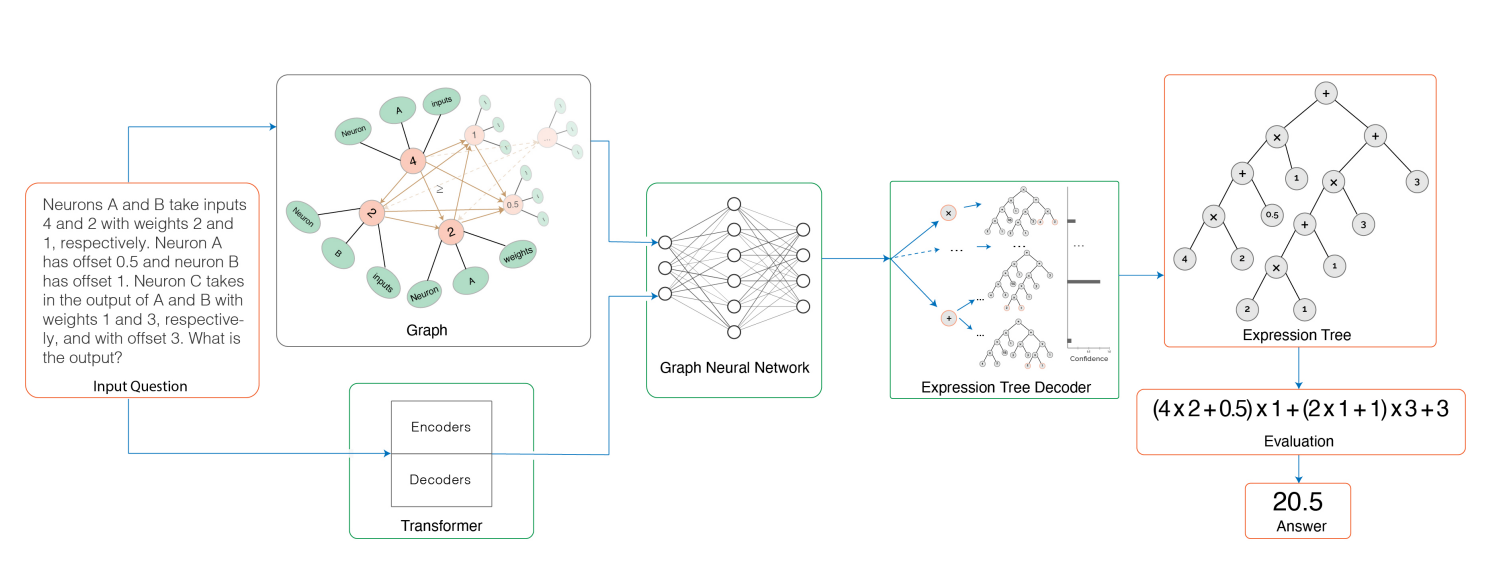
A lot of the benefit seems to come from the data augmentation:
After collecting questions from 6.036 homework assignments, exercises, and quizzes, each question is augmented by paraphrasing the question text. This results in five variants per question. Each variant, in turn, is then augmented by automatically plugging in 100 different sets of values for variables. Overall, we curate a dataset consisting of 14,000 augmented questions.
One thing that's a bit dissapointing is that coding questions are skipped. In my opinion well-formulated coding questions are the best part of classes, since they force you to replicate the content and really understand it. Maybe a tandem team with OpenAI Codex can pass the course in full.
What makes something interesting?
In open-endedness research, we want to build systems that can keep producing unbounded amounts of interesting things. There are many problems with this definition. What qualifies as unbounded? What makes something interesting? What makes something a thing?
One answer is that all these questions depend on the perspective that we look at the world in. Alyssa M Adams' talk at Cross Roads this month gives an example:
The sea was never blue. Homer described the sea as a deep wine color. The greek color experience was made of movement and shimmer, while modern humans care about hue, saturation and brightness.
It's a representation learning problem! Interestingness isn't a fact by itself, an object is only interesting to the agent that is looking at it. Normally, this answer isn't that satisfying, since modeling what is interesting to humans is expensive at best and inaccurate at worst.
With the rise of foundation models, however, we can make a non-trivial argument that AI models like GPT-3 and CLIP are learning strong human-centric representations of reality. Could we just, like, ask these models what they think is interesting?
Maybe GPT-3 thinks "walking" and "running" are too similar, but "flying" is qualitatively different. Maybe CLIP thinks a truck is a truck regardless of what roads it's on, but if the truck is in the ocean, now that is interesting.
Interestingness in Architecture
"Nearly everything being built is boring, joyless, and/or ugly", writes Nathan Robinson. In an April article, Robinson showcases colorful classical temples, mosques, and coastal villages. Then he shows photographs of modern brutalist design – cold and gray.


What is beauty? Beauty is that which gives aesthetic pleasure ... a thing can be beautiful to some people and not to others. Pritzker Prize-winning buildings are beautiful to architects ... They are just not beautiful to me.
Hey, look, it's the problem of interestingness again. What makes a building lively, welcoming, or as Christopher Alexander puts it, contains "the quality without a name"? There's probably no objective answer, but there is a human-centered answer. Could an AI understand architectural aesthetics? If it has the right representations, I don't see why not.