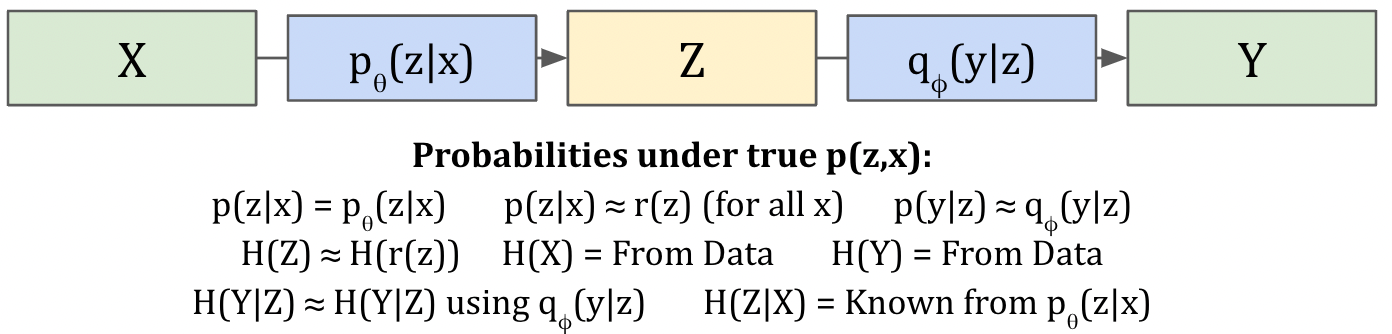
Let's take a look at neural networks from the perspective of information theory. We'll be following along with the paper Deep Variational Information Bottleneck (Alemi et al. 2016).
Given a dataset of inputs and outputs , let's define some intermediate representation . A good analogy here is that is the features of a neural network layer. The standard objective is to run gradient descent so to predict from . But that setup doesn't naturally give us good representations. What if we could write an objective over ?
One thing we can say is that should tell us about the output . We want to maximize the mutual information . This objective makes natural sense, we don't want to lose any important information.
Another thing we could say is that we should minimize the information passing through . The mutual info should be minimized. We call this the information bottleneck. Basically, should keep relevant information about , but discard the rest of .
The tricky thing is that mutual information is hard to measure. The definition for mutual information involves optimal encoding and decoding. But we don't have those optimal functions. Instead, we need to approximate them using variational inference.
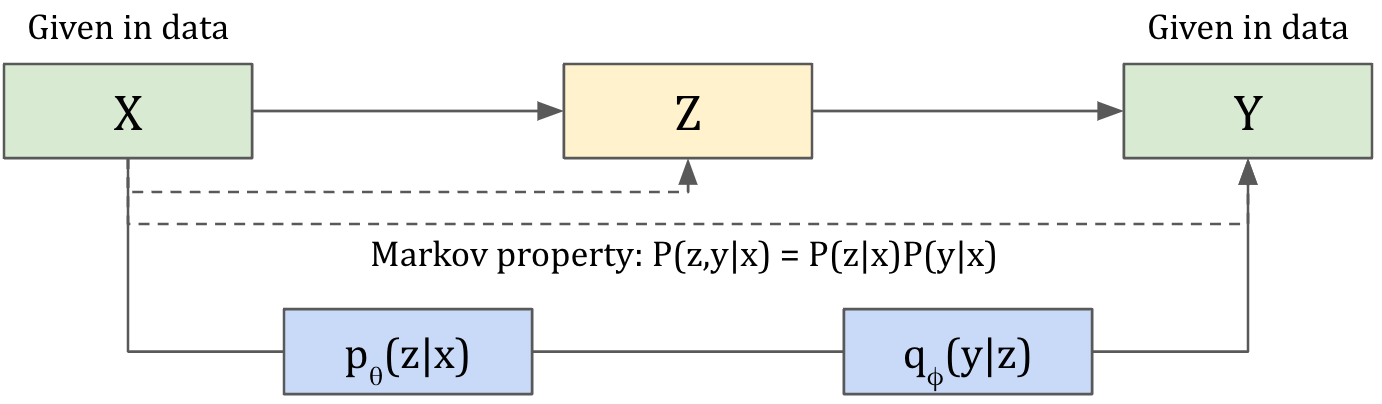
Let's start by stating a few assumptions. First we'll assume that X,Y,Z adhere to the Markov chain (Y - X - Z). This setup guarantees that P(Z|X) = P(Z|X,Y) and P(Y|X) = P(Y|X,Z). In other words, Y and Z are independent given X. We'll also assume that we're training a neural network to model p(z|x).
Information Bottleneck Objective
Here's our main information bottleneck objective ( determines the "strength" of the bottleneck):
.
We'll break it down piece by piece. Looking at the first term:
(Definition of conditional entropy.)
The H(Y) term is easy, because it's a constant. We can't change the output distribution because it's defined by the data.
The second conditional term is trickier. Unfortunately, p(y|z) isn't tractable. We don't have that model. So we'll need to approximate it by introducing a second neural network, q(y|z). This is the variational approximation trick.
The key to this trick is recognizing the relationship between and KL divergence. KL divergence is always positive, so . That means we can plugin q(y|z) instead of p(y|z) and get a lower bound. Another way to interpret this trick is: H(Y|Z) is the lowest entropy we can achieve using in the optimal way. If we use in a sub-optimal way, that's an upper bound on the true entropy. The overall term is lower-bounded because we subtract H(Y|Z).
Because of the Markovian assumption above, we can break down p(y,z) into p(y|x)p(z|x). This version is easier to sample from.
Let's look at the second term now. We will use a similar decomposition.
This time, the second term is the one that is simple. We have the model p(z|x), so we can calculate the log-probability by running the model forward. The p(z) term is tricky. It's not possible to compute p(z) directly, so we approximate it with r(z). The same KL-divergence trick makes this an upper bound to H(Z).
Putting everything together, the information bottleneck term becomes:
It's simpler than it looks. We can compute an unbiased gradient of the above term using sampling. Once we sample , we can calculate p(y|x) and p(z|x) by running the model forward. The second term is actually a KL divergence between p(z|x) and r(z), which can be computed analytically if we assume both are Gaussian.
Thus the objective function can be written as:
Intuitions
Let's go over some intuitions about the above formula.
-
The first part is equivalent to maximizing mutual information between Y and Z. Why is this equivalent? Mutual information can be written as . The first term is fixed. The second term asks "what is the best predictor of Y we can get, using Z"? We're training the network to do precisely this objective.
-
The second part is equivalent to minimizing mutual information between and . Why? Because no matter which is sampled, we want the posterior distribution to look like . In other words, if this term is minimized to zero, then p(z|x) would be the same for every . This is the "bottleneck" term.
-
The variational information bottleneck shares a lot of similarities with the variational auto-encoder. We can view the auto-encoder as a special case of the information bottleneck, where Y=X. In fact, the VAE objective is equivalent to what we derived above, if y=x and .
If we set X=Y, one could ask, isn't it weird to maximize ? It's just zero. The answer is that we're optimizing different approximations to those two terms. The first term is the recreation objective, which optimizes a bound on H(X|Z). The second is the prior-matching objective, which optimizes the true H(Z|X) and a bound on H(Z).
-
What extra networks are needed to implement the variational information bottleneck? Nothing, really. In the end, we're splitting y=f(x) into two networks, p(z|x) and q(y|z). And we're putting a bottleneck on via an auxiliary objective that it should match a constant prior r(z).