In open-endedness research, we care about building systems that continously generate interesting designs. So what makes something interesting? Previously, I argued that interestestness depends on a viewer's perspective. But this answer isn't very satisfying.
Ideally, we would want some mathematically-definable way to measure how interesting something is. A naive approach would to be to define interestingness as variation or entropy, but we run into the following problem:
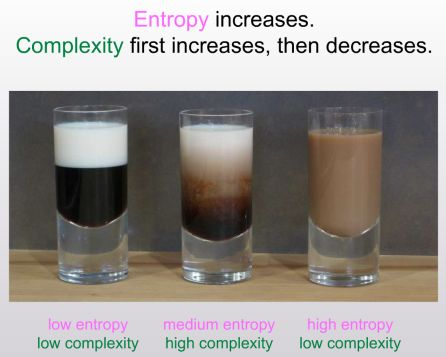
In this example, you get the highest entropy by mixing milk and coffee, since at the molecular level the particles are the most widely distributed. But somehow the middle cup is the most interesting to us as humans, since the half-mixed milk forms all sorts of cool swirls and twists.
An analogy I like to draw here is the 10,000 oatmeal problem, which states:
I can easily generate 10,000 bowls of plain oatmeal, with each oat being in a different position and different orientation, and mathematically speaking they will all be completely unique. But the user will likely just see a lot of oatmeal.
Entropy is not all that great! Sure, we get a lot of unique designs, but at some level they all look like the same design. Something is missing in our interestingness formulation.
The best definition of interestingness I've come across so far is the idea of sophistication, which is mentioned in this blog post by Scott Aaronson:
Sophistication(x) is the length of the shortest computer program that describes, not necessarily x itself, but a set S of which x is a “random” or “generic” member.
Sophistication solves our milk-coffee problem and our oatmeal problem. In both cases, the high-entropy examples can be described by very short programs – just sample random positions for each particle. Something like the swirls in the half-mixed cup has higher sophistication, since you'd need a more complicated program to generate those artifacts.
How can we apply sophistication in the context of open-endedness and machine learning? Let's say we're trying to generate a lot of interesting image. One formulation is to do something like:
- An image gets less reward the more times it is generated.
- Continously search for high-reward images.
Obviously, this formulation kind of sucks, since the space of images is really big, and we will basically end up with a lot of images of noise. Ideally, we want to eliminate all images that look like 'static noise' in one swoop, and move on to more interesting kinds of variation.
Here's a sophistication-like formulation that makes use of smarter learning:
- A generative adversarial network is trained to model all past images that have been generated.
- An image gets less reward if the GAN's discriminator thinks it looks in-distribution.
- Continuously search for high-reward images and re-train the GAN.
In theory, this GAN-based formulation should explore the image space in a more efficient manner. Once a few static-noise images have been generated, the GAN can model all types of static-noise, so high-reward images need to display other kinds of variation.
The GAN-based formulation kind of resembles sophistication, where we assume that Soph(x) is just -Disc(x), i.e. an image is sophisticated if it the GAN struggles to model it correctly. As long as we're continously re-training our GAN, this approximation shouldn't be too bad.
(To be continued...)